Rise of Symmetric Systems
For a long time we have been building software in a very standard fashion, put a web server in the front, a big application server and a standard backing database. This is the standard layered architecture. Most application stacks Rails or .Net for example assume a single database server, a few application servers, some web servers and a load balancer.
But as ‘webscale’ and ‘elastic scaling’, ‘commodity hardware’ have become buzzwords, there has been a quiet change in the way systems are being designed. Some people are calling it ‘Symmetric Systems’.
In a nutshell, ‘Symmetric Systems’ is fitting the whole application stack on a single machine. The database, application server and web server are running on the same machine, hence it is completely self contained. If the application stack is crammed into one machine, then there is only limited amount of ‘juice’ left on the machine to service thousands of requests we all aspire to service. The scaling in these cases are achieved by adding a large number of such instances.

photo credit: southerncomfort
One of the systems I am currently working on, is symmetric. It has a very simple model as you can see from the figure below, each request is passed by the ELB to Nginx on any machine and passed all the way to Rails that interacts with CouchDB. The data is synchronized by CouchDB instances via replication.
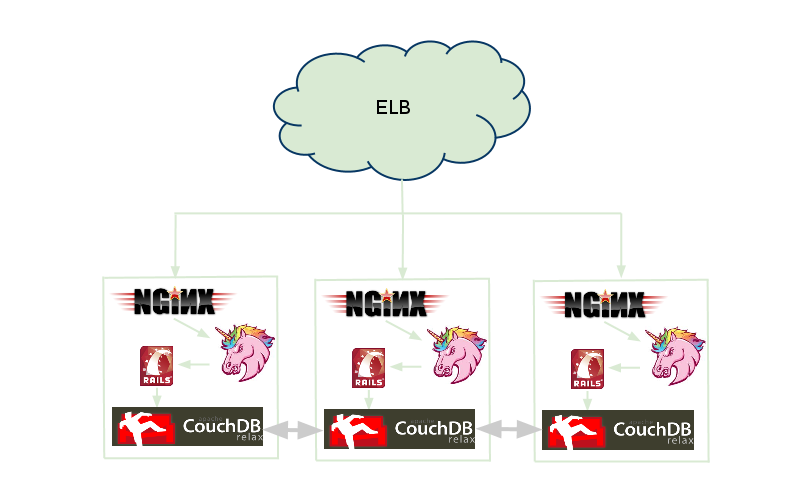
This has been a thought shift for me, where in my previous life, I’ve been scaling systems by breaking it down into smaller components, that can be hosted individually. For example, in the ticketing system that I had worked on before, the booking service was hosted on one machine, the customer service was on another machine and the ticketing service on another. That way the load could be distributed across the application. Really? What about the network call overhead across the services? What about complexity of network of interactions? Remember Metcalfe’s law. There are ways to deal with those things but that leads to inevitable increase of complexity.
Benefits
Elastic scaling:
This should come as no surprise. Most of the times, choosing an hardware is a matter of guess about how many people are going to use the system and how the number of people will increase. These guesses are expensive to get it wrong. Instead there has been a large scale move to the cloud where you get instant instances and as load increase it is trivial to increase the number of machines serving out the application. In Theory, such systems can scale linearly to handle load.
No Single point of failure:
If a machine goes down, it just reduces our load bearing capacity, it does not cripple the system in case of Non Symmetric design, where if the ticketing service goes down, the application is down. This has a direct impact on the simplicity of the system. There are no backup machines no slaves to manage and deal with.
Locality of code and data:
Since the whole stack on the same machine, there are no expensive network calls to talk to the database and to other components. This means faster and highly predictable response times.
Deployment:
Because all the stack is on one machine deployment is trivial, Copy the code, and start the services. Our deploy.rb (other than standard sets for rvm and bundler)
after "deploy:restart" , "bluepill:restart"
That’s it. We also have ZERO deployment downtime, To redeploy we have the following instructions
cap elb:unregister
cap deploy
rake production_tests
cap elb:register
Rinse and repeat till all the machines are upgraded.
This personally is one of the single biggest win as developer(#devops). On a similar scale .Net application I worked on we had downtime window of 4hrs in the wee hours of morning to deploy and verify stuff was working on each component. And after a few hours of deployment of each component, we’d realize the whole system was not working because of a step forgotten on one component. I really really dread those deployments, so did everybody else. Eventual result we deployed every 3 months and that just made it worse.
Consistent Environments:
Developers QA’s and the production environments are exactly the same. the number of machines in each environment. The only thing missing in the development environment is ELB. This means the app is being tested by everybody and in the same way. Unlike the weird bugs you see only in testing and production environments, where the components are wired up differently or have incorrect wiring up.
No Versioning issues:
One of big problems with the divide an conquer approach is versioning of components in the system. Such systems inevitably need to version individual components and that means incompatible versions won’t work together properly and break in rather weird ways. Add one more layer of complexity to manage all of this.
Symmetric systems don’t have this issue, all of it is released in one go on a single machine.
Drivers
Low footprint databases, application and web servers:
Oracle or Sql Server need dedicated hardware and needs to run on separate machine, I don’t know if that is strictly true, but definitely the pitch i have heard from the vendors. These days we have some serious options for running small databases on commodity hardware. No, i’m not talking about Sqlite or Prevayler. CouchDB, Redis, MongoDB all fit the bill for such databases and they are really fast but still battle hardened databases.
Amazon EC2 and friends:
The Amazon Dynamo paper is one of the key proponents of Symmetric systems. Amazon’s architecture is based on dynamo, and it is no surprise that a lot of features it offers expect systems to be symmetric. For example, Cloudwatch is easiest to use if a system is symmetric.
Simplified Clustering/Replication of data:
Every NoSql database worth it’s salt provides either clustering or replication or both of data. This means data does not have to live in a central database, it can be distributed over a cluster.
The hard stuff
All things can’t be Distributed
We have a Resque process that runs expiry of certain type records in couchdb every day. We have not found a simple way of distributing this on each machine, without duplication and conflicts. Such things are on a random instance picked up from a central redis queue.
Deployments are slightly hard
We use Capistrano, the default model is to deploy remotely to a set of machines labelled web, app and database, what we really wanted was to deploy the whole thing to one machine, that we just created by Amazon Auto Scaling. We have a hacky solution to this, and it took me a few days of head scratching to get right. I’d interested in seeing how other people are doing it.
Monitoring has to deal with lot more machines
The simple things are generally covered by your cloud provider, but application specific stuff is harder to deal with. For example debugging failures are much harder, because you never know which machine the request went to. We consolidate logs from each machine in one place, and review them periodically.
Can we fit the whole app on the same machine?
There are apps that just won’t fit into a single machine, because of the earlier architectural decisions. We have been very aggressive with our choice of software to run on our machines. Apache is out because it takes a lot of memory, Nginx is our choice of Web server because of it’s efficiency. Any other way we’d be putting out Bloatware.